This work was conducted under the supervision of Prof. Babak Salimi, with advising from PhD students Parjanya Prashant and Jiongli Zhu.
Agents need tools. The MCP ecosystem now has thousands of community-contributed endpoints, and that number is growing fast. The problem is not finding tools that match a query. It’s finding tools that work. Multiple endpoints claim to do the same thing with near-identical descriptions, but they differ wildly in reliability. They look the same on paper, semantically indistinguishable, yet one succeeds 95% of the time and the other crashes on half its inputs. ToolFlix is a recommender system for MCP tools: it learns from execution history to rank tools by how well they actually perform, not just how well their descriptions match.
Why retrieval isn’t enough
Every existing approach to tool selection operates on static, description-level information. Retrievers rank by semantic similarity. Rerankers use structural priors or LLM-based scoring. Discovery systems improve query formulation. None of them learn from whether a tool actually succeeded.
This matters because tool descriptions lie. Consider two real search endpoints from our pool:
Figure 1. Two search tools with near-identical descriptions. A retriever ranks them interchangeably. Only execution feedback reveals the difference.
A retriever sees two tools that both say “search” and ranks them interchangeably. No amount of better retrieval fixes this. You need execution feedback.
What I built
ToolFlix is a recommender system for MCP tools, built as a two-stage retrieve-then-rerank pipeline that learns from execution feedback. The retriever casts a wide net (top 100 by hybrid cosine + keyword scoring), then a learned reranker selects the top 5 to present to the agent. After each tool call, an LLM judge evaluates the execution result, determining whether the tool actually accomplished the task or produced garbage. These judgments become the training signal that teaches the reranker which tools are reliable and which merely look good on paper.
The reranker has 68K parameters and two prediction heads sharing a deep trunk. The deep trunk takes query and tool description embeddings, projects them through learned matrices, computes interaction features (cosine similarity, element-wise product, difference), and includes a learned endpoint embedding that starts from the description but diverges through training to encode what the tool actually does rather than what its description claims.
The two heads read different subsets of these features. The relevance head sees only the deep trunk output. No access to execution statistics. It’s forced to learn query-tool affinity entirely through embeddings, capturing patterns like “fetch tools work for search tasks, but this specific fetch tool fails on news sites.” Think of it as the personalized recommendation. The quality head sees the deep trunk output plus six wide features: success rate, usage count, co-occurrence with query categories, and retriever similarity. It memorizes per-tool reliability. Think of it as the star rating.
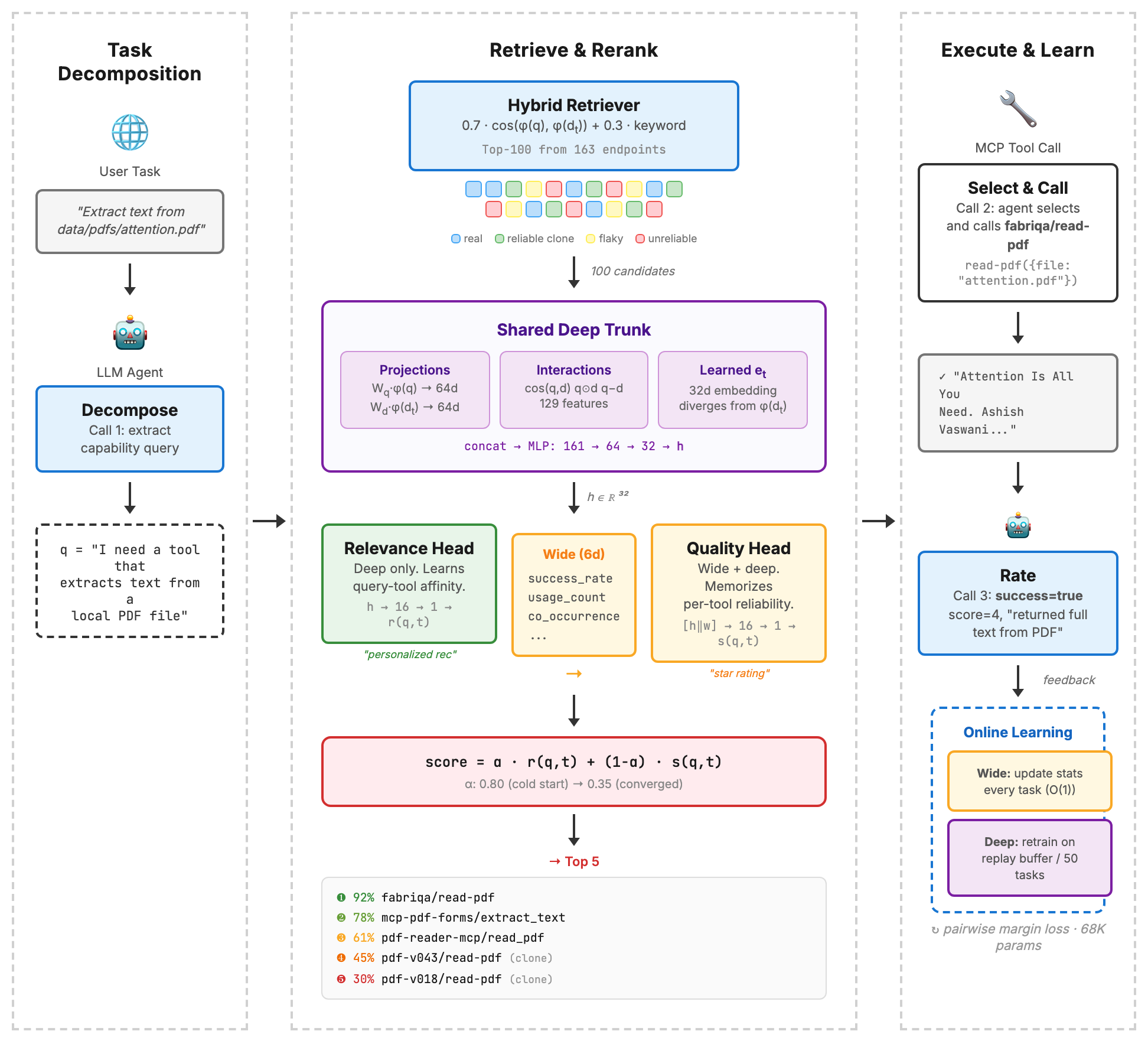
The final score blends both heads: alpha * relevance + (1 - alpha) * quality. Alpha starts at 0.80 (trust embeddings at cold start when there are no execution stats) and decays to 0.35 as feedback accumulates. I found 0.35 optimal at convergence. Pure quality ignores query-tool affinity. Equal weighting gives too much influence to the noisier relevance signal.
Training uses pairwise margin loss over execution outcomes as judged by the LLM. After each tool call, the judge scores the result: did the tool return a useful, complete response, or did it fail, truncate, or return stale data? When a tool succeeds, it should rank above the other candidates. When it fails, others should rank above it. This closes the feedback loop—the recommender system improves its rankings based on observed tool performance, not static metadata. The key detail: the relevance head trains with zeroed wide features, forcing it to learn through embeddings alone. Three-phase training (relevance, then quality, then joint fine-tuning) prevents either head from dominating the shared trunk.
The evaluation problem
Real MCP tools absolutely have quality variance—the DuckDuckGo example above is one of many. But our initial pool of 59 endpoints was too small to surface enough variance within each category for the reranker to demonstrate its value. So I built a synthetic benchmark. I took those 59 real endpoints across 16 MCP servers and created 104 synthetic variants with paraphrased descriptions and controlled failure modes: random failures (35% of calls return errors), truncated responses (first 80 characters only), and stale responses (canned error messages 60% of the time). Opaque tool IDs prevent the agent from inferring quality from names. All tool calls go through real MCP execution, with failure injection applied transparently.
This creates exactly the problem. Tools with nearly identical descriptions but success rates ranging from 0% to 95%. The retriever cannot distinguish them. Only execution feedback reveals which variants are reliable.
Results
I trained on 2,000 tasks (500 per category: fetch, PDF, search, filesystem) and evaluated on 200 held-out tasks.
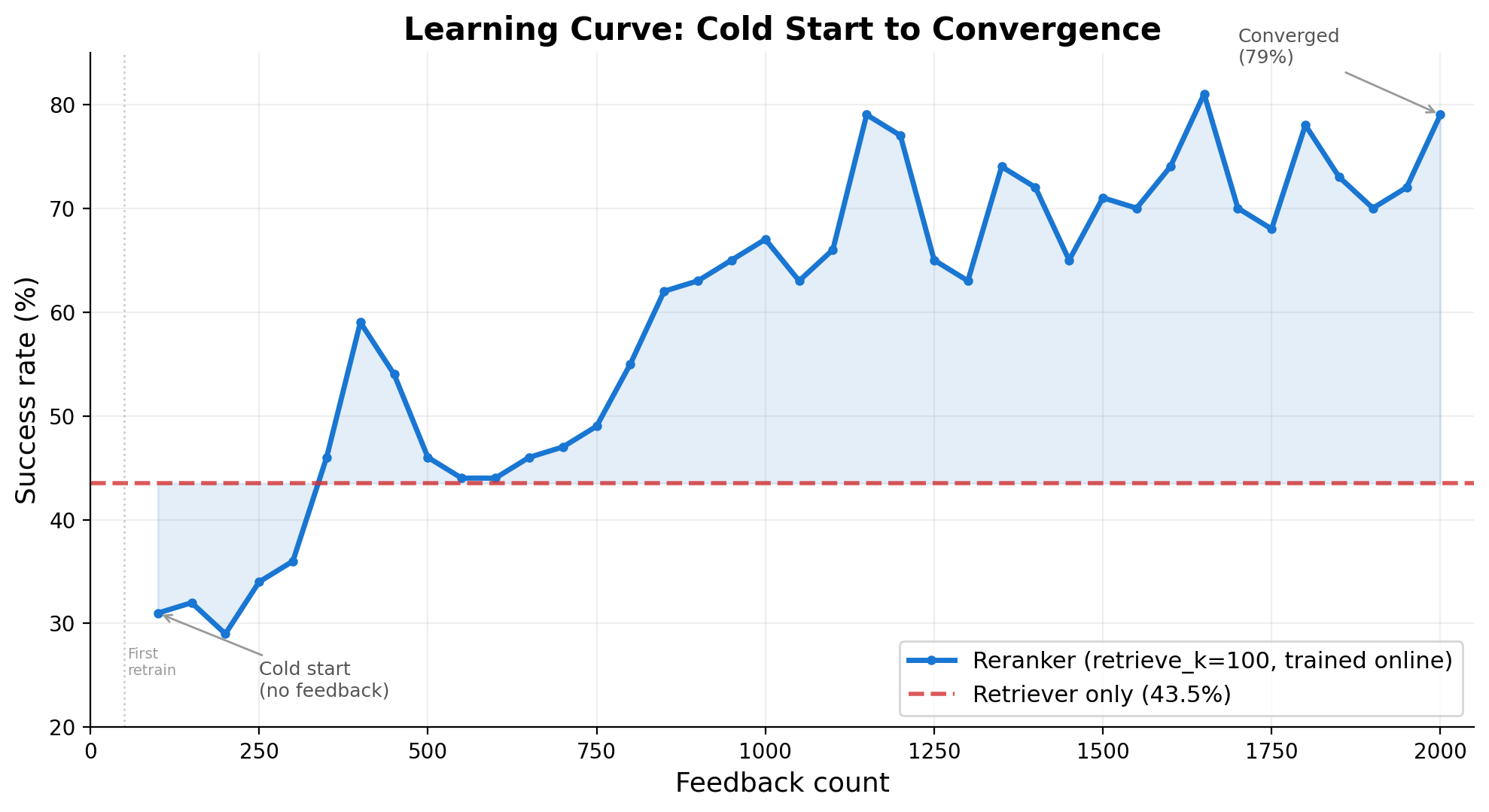
The held-out comparison tells the clearest story. The retriever alone achieves 43.5% success on the noisy 163-endpoint pool. The reranker, trained on execution feedback, reaches 70.0%. That’s a 26.5 percentage point lift. The gains concentrate where the problem is worst: search improved from 22% to 72%, fetch from 32% to 70%.
| Retriever (clean) | Retriever (noisy) | Reranker (noisy) | |
|---|---|---|---|
| Overall | 64.3% | 43.5% | 70.0% |
| Fetch | 72% | 60% | 70% |
| 82% | 50% | 78% | |
| Search | 46% | 22% | 72% |
| Filesystem | 58% | 54% | 60% |
Figure 4. Three-way comparison on 200 held-out tasks. The reranker with the noisy pool outperforms the retriever with a curated pool (70% vs 64.3%). You don’t need to curate your tool marketplace if you learn from feedback.
The most surprising result: the reranker operating on a noisy pool (163 endpoints, many unreliable) outperforms the retriever operating on a clean, curated pool (81 endpoints, only reliable tools). 70.0% vs 64.3%. The reranker doesn’t just overcome the noise. It exceeds what curation alone achieves, because it learns query-specific patterns that description similarity misses.
Limitations and what’s next
The synthetic benchmark isolates the learning signal but doesn’t capture real-world quality distributions. The evaluation pool (163 endpoints) is small compared to real marketplaces. The agent-in-the-loop introduces noise since it overrides the reranker’s ranking roughly 45% of the time. Search coverage depends heavily on retriever recall, and some good tools never enter the candidate set for certain queries.
I’m working on a simulated marketplace benchmark (500to1,000 tools) to test scaling, ablation studies on quality drift and cold-start scenarios for new tools, and validation against human tool quality annotations. I also plan to strip redundant wide features (category match and retriever similarity are already captured by the deep trunk) and test whether a slimmer model performs comparably.
Full paper targeting NeurIPS 2026. Preprint forthcoming.